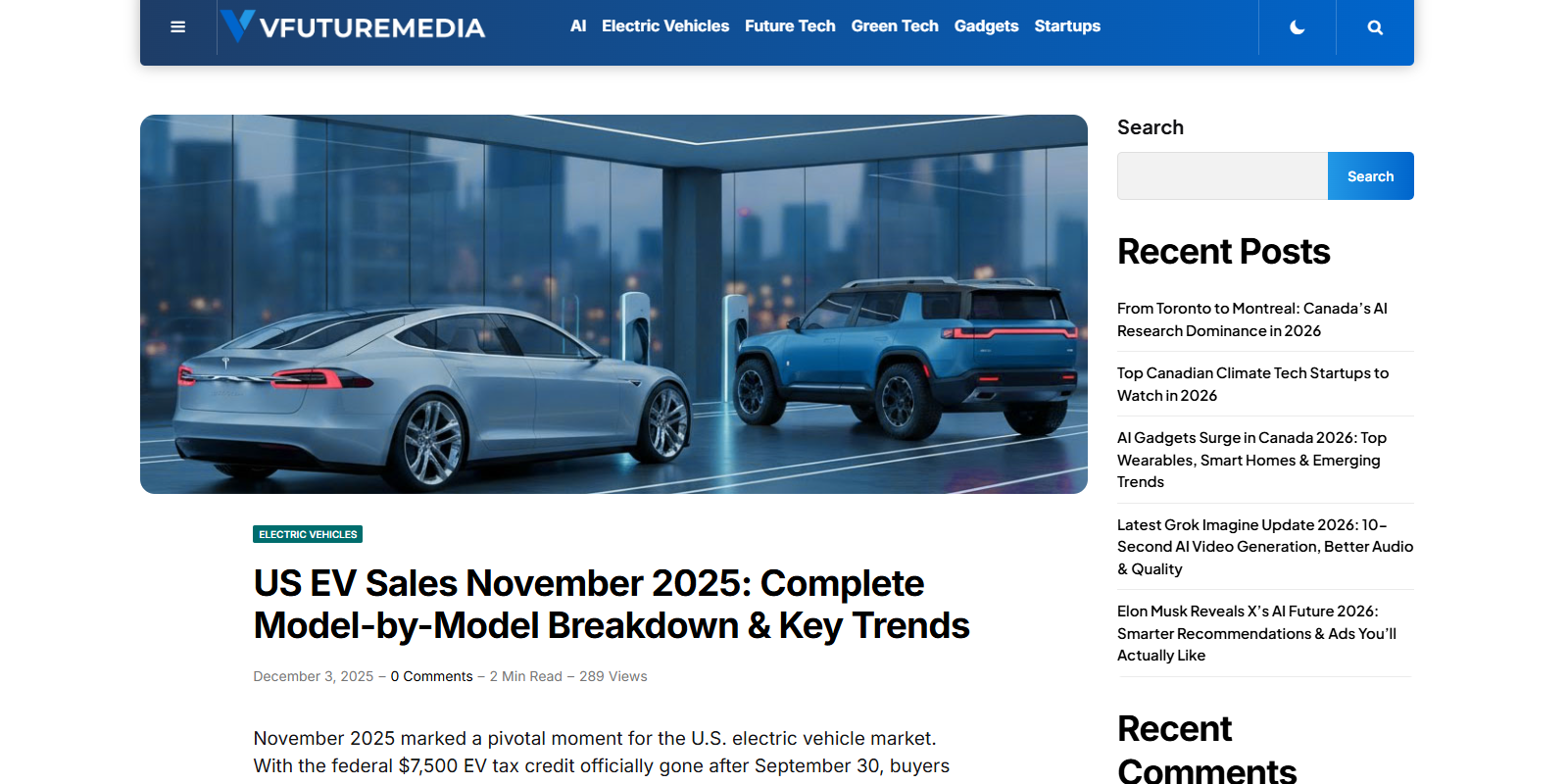
How to Get ChatGPT to Recommend Your Business in 2026: 10 Small Sites That Did It
Update at 01/27/2026 by Luiz Gustavo
You probably have a small website and you're wondering: how the heck do I get ChatGPT to recommend my business?
I'll be honest with you, it's not super easy, but it's definitely possible. While traditional SEO focuses on Google rankings, generative engine optimization (GEO) is about getting cited by AI search tools like ChatGPT, Perplexity, and Claude. ChatGPT does prioritize high-authority websites in most cases, but there are outliers. And today, we're exploring exactly those small sites that cracked the code for SEO for ChatGPT.
The 10 Small Websites That Actually Get ChatGPT Citations
I want to start with the fun part, the actual sites. These sites are getting recommended because they're doing specific things right. Let me break down each one so you can see exactly what's working.
Question answered"Which affiliate marketing niches are most profitable this year?"
Publication year2025
Length2,779 words
What Makes It Stand Out
• Unique Angle (17/20 - Exceptional)
• Original Research (8/10 - Strong)
• Nuanced Analysis (5/5 - PERFECT)
• Technical Depth (19/20 - Near perfect)
• Dense Vocabulary (29.33% long words - highest in top 10)
• Well Structured (P/Div 2)
• Complete Answer (10/10)
• Recent Content (2025)
Why It Was Cited
Second-best overall score (81.45/100) driven by exceptional vocabulary density:
Best vocabulary density (29.33% long words) - Highest percentage of technical terms in entire top 10
Near-perfect expertise (19/20) - Deep industry knowledge with specific data
Perfect nuance (5/5) - Balanced analysis with pros, cons, and exceptions
Competitive edge: Most technical vocabulary of any site analyzed. Despite moderate length (2,779 words), achieves maximum density with specialized affiliate marketing terminology.
Question answered"How much does a house cost in Miami?"
Publication year2025
Length1,175 words
What Makes It Stand Out
• Unique Angle (15/20 - Strong)
• Original Research (7/10 - Good)
• Nuanced Analysis (4/5 - Strong)
• Technical Depth (18/20 - Excellent)
• Dense Vocabulary (TTR 0.423 - very high, 17.36% long words)
• Complete Answer (10/10)
• Recent Content (2025)
• Concise (1,175 words - efficient)
Why It Was Cited
Fourth-place score (71.44/100) with efficiency and local expertise:
High TTR (0.423) - Excellent vocabulary diversity for a concise article
Local market data (7/10) - Proprietary Miami real estate insights
Excellent expertise (18/20) - Deep real estate market knowledge
Competitive edge: Short but dense. Packs Miami real estate expertise into 1,175 words without dilution, maintaining high vocabulary diversity (TTR 0.423).
Question answered"What supplements are popular in 2025?"
Publication year2025
Length2,805 words
What Makes It Stand Out
• Unique Angle (14/20 - Good)
• Original Research (8/10 - Strong)
• Nuanced Analysis (4/5 - Strong)
• Technical Depth (17/20 - Excellent)
• Dense Vocabulary (TTR 0.4011, 22.53% long words)
• Complete Answer (10/10)
• Recent Content (2025)
Why It Was Cited
Fifth-place score (71.31/100) with solid research foundation:
Strong proprietary data (8/10) - Original supplement research and analysis
High vocabulary density - 22.53% long words (above top 10 average)
Excellent expertise (17/20) - Health science knowledge with technical terms
Competitive edge: Balanced profile across all dimensions. No single exceptional metric, but consistent strength in research (8/10), expertise (17/20), and vocabulary density (22.53%).
#6 - instadlbot.com
⭐⭐⭐⭐
DR (Domain Rating)0
NicheSocial Media/Instagram Marketing
Question answered"What Instagram content formats perform best in 2025 for affiliates?"
Publication year2025
Length5,478 words
What Makes It Stand Out
• Unique Angle (16/20 - Strong)
• Original Research (6/10 - Moderate)
• Nuanced Analysis (5/5 - PERFECT)
• Technical Depth (18/20 - Excellent)
• Specialized Jargon (77 acronyms - second highest)
• Complete Answer (10/10)
• Recent Content (2025)
Why It Was Cited
Sixth-place score (68.66/100) with perfect nuance:
Perfect nuance (5/5) - One of only 3 sites with maximum nuance score
Second-most acronyms (77) - Heavy Instagram/social media terminology
Extensive content (5,478 words) - Second-longest article in top 10
Competitive edge: Ultimate efficiency. Achieves TTR 0.537 (highest in top 10) in only 663 words, proving that density matters more than length for LLM citations.
• Specialized Jargon (109 acronyms - highest in top 10 tie)
• Complete Answer (10/10)
• Recent Content (2025)
Why It Was Cited
Ninth-place score (57.8/100) with jargon expertise despite no proprietary data:
Most acronyms (109) - Tied for highest technical abbreviation count
Excellent expertise (16/20) - Deep drone technology knowledge
Zero proprietary data (0/10) - Yet still cited due to expertise and jargon
Competitive edge: Proves that original research isn't mandatory. Compensates for lack of proprietary data (0/10) with exceptional technical jargon (109 acronyms) and expertise (16/20).
Question answered"What are the most popular electric cars right now?"
Publication year2025
Length527 words
What Makes It Stand Out
• Unique Angle (12/20 - Moderate)
• Original Research (5/10 - Moderate)
• Nuanced Analysis (3/5 - Adequate)
• Technical Depth (14/20 - Good)
• Dense Vocabulary (TTR 0.6243 - highest in top 10)
• Complete Answer (10/10)
• Recent Content (2025)
• Concise (527 words - shortest in top 10)
Why It Was Cited
Tenth-place score (56.3/100) with extreme vocabulary efficiency:
Highest TTR ever (0.6243) - Exceptional vocabulary diversity, highest in all top 10
Shortest article (527 words) - Most concise, yet maintains quality
Perfect answer (10/10) - Complete response in minimal words
Competitive edge: Maximum compression. Achieves extraordinary TTR 0.6243 in only 527 words, proof that ultra-concise, vocabulary-dense content can compete with longer articles for LLM citations.
What Actually Works: ChatGPT SEO Optimization Fundamentals
Before diving into the numbers, here's how we've made this research (for the full methodology, check the end of this article):
Understanding ChatGPT SEO optimization requires a different approach than traditional search engine optimization. We analyzed 60 low-authority websites (all with Domain Rating < 15) across 74 different metrics to decode what makes content citable by AI search engines.
The setup: For each of 30 different questions (like "What supplements are popular in 2025?" or "Which affiliate niches are most profitable?"), we found:
One website that ChatGPT cited when using its web search tool
One random website covering the same topic that ChatGPT did not cite
We then analyzed these 60 sites across 74 metrics including originality, vocabulary density, HTML structure, schema markup, answer completeness, recency, and traditional EEAT signals.
So, now that our research is done, what are the main patterns that we found out? Let's break it down.
Originality Beats Optimization
This is the big one. When we scored sites for originality, the top performers averaged 77.1% (61.7 out of 80 points) and this single factor carried more weight than anything else. But what does "originality" actually mean to an LLM?
Anatomy of Perfect Originality
Case study: robertyoung.consulting (#1 ranked)
78/80 Points (97.5%)
Unique Angle
Novel approach vs standard coverage of supplements
90% Score
Proprietary Data
Original research vs curated content
100% Perfect ⭐
Nuanced Analysis
Acknowledges trade-offs and complexity
100% Perfect ⭐
Demonstrated Expertise
Technical depth and insider knowledge
100% Perfect ⭐
Why This Site Won
robertyoung.consulting achieved the highest originality score in our entire study by combining three rare elements:
Perfect proprietary data (10/10) - Only site in top 10 with maximum score in original research
Flawless technical expertise (20/20) - Demonstrates deep knowledge with specialized terminology (81 acronyms)
Perfect nuance (5/5) - Acknowledges trade-offs and complexity rather than making simplistic claims
The Contrast
Compare this to the average random site: ~35/80 points (43.8%). The difference? Random sites curate existing information. This site created new knowledge. That's what originality means to an LLM.
We broke it down into four concrete criteria:
1. Unique Angle (out of 20 points)
2. Proprietary Data (out of 10 points)
3. Nuanced Analysis (out of 5 points)
4. Demonstrated Expertise (out of 20 points)
Real Example: What Originality Looks Like
Let's compare two approaches to "What supplements are popular in 2025?"
Generic approach (low originality):
Lists creatine, protein, vitamin D (everyone knows these)
Explains molecular mechanisms with technical precision (expertise: 20/20)
Score: 78/80 (this is robertyoung.consulting's actual approach)
The difference? The second one couldn't be written by someone who spent an afternoon Googling. It required genuine expertise, original research, and a unique perspective.
The Takeaway
Originality isn't about being contrarian or clickbaity. It's about:
Approaching topics from angles others haven't explored
Contributing data or analysis nobody else has
Acknowledging complexity and trade-offs honestly
Writing with genuine domain expertise
Optimizing for search engines is not enough. Start having something new to say, backed by real data, explained with actual expertise. That's what will help you to get cited in the age of AI search.
Fresh Content is King (and We Mean *Really* Fresh)
This was our 2nd biggest finding. 83.3% of cited sites were published in 2025 (the current year), compared to only 23.3% of random sites (answering the same questions). That's a +257% differencethe single biggest gap we found in the entire study.
Only Current Year Content Gets Cited
Publication year distribution: Cited vs Random sites
2019-2023
5
Cited sites
15
Random sites
2024
0
Cited sites
8
Random sites
⚠️ Zero citations
Even 1-year-old content struggles
2025 ✓
25
Cited sites (83.3%)
7
Random sites (23.3%)
+257% Difference
Current year content (2025) has a massive citation advantage. Even content from 2024 received zero citations in our study, making freshness the single biggest factor for AI search visibility.
Cited by ChatGPT
Not cited (random)
But here's the kicker: even content from 2024 (just one year old) barely gets cited. We found zero cited sites from 2024, while random sites had 8. ChatGPT wants content from this year, not just "recent" content.
The takeaway: If your article says "In 2023..." or "Last year...", you're already losing. Update that date, refresh your examples, and make it scream "2025" or "2026."
This makes sense when you think about it: when ChatGPT uses its AI search tool, it's looking for fresh information that's not already in its training data, making recency a critical factor in any generative engine optimization strategy.
Rich Vocabulary Signals Expertise
Sites that got cited used 15.76% more diverse vocabulary (measured by Type-Token Ratio). They also used:
19.6% more long words (8+ characters)
24.7% more technical acronyms (AI, API, SaaS, etc.)
14.64% higher content word ratio (less fluff, more substance)
Cited Sites Use Richer Vocabulary
Vocabulary density comparison across all metrics
Type-Token Ratio (TTR)
Unique words / total words · Higher = more diverse vocabulary
Cited
0.4619
Random
0.399
+15.76%
Long Words Percentage
Words with 8+ characters (excluding stopwords)
Cited
17.87%
Random
14.94%
+19.6%
Technical Acronyms
Average count per article (AI, API, SaaS, etc.)
Cited
28.7
Random
23.03
+24.7%
Content Word Ratio
Nouns/verbs/adjectives vs function words · Higher = less fluff
Cited
0.525
Random
0.458
+14.64%
Key Insight
Cited sites consistently show 15-25% higher vocabulary density across all metrics. They use technical terminology naturally, signaling genuine expertise rather than surface-level knowledge.
And here's the plot twist: cited sites were actually shorter on average (1,493 words vs 1,960 words for random sites). They just packed more punch into fewer words.
Quality Over Quantity
Cited sites are shorter but score higher
Word Count Difference
-23.8%
Cited sites are shorter
Score Difference
+57.8%
But score much higher
Shortest Cited
527
words (vfuturemedia)
The Takeaway
Cited sites are 23.8% shorter but score 57.8% higher. They pack more value into fewer words, proving that density and expertise matter more than hitting arbitrary word counts. Quality over quantity, every time.
Think about it, when you read something written by a true expert, they use precise terminology naturally.
The takeaway: Don't dumb down your writing. Use technical terms when appropriate. Show your expertise through language sophistication, not word count.
Semantic HTML Structure Matters (But Not How You Think)
Random sites actually had more HTML structure, more headings, more paragraphs, more everything. But cited sites had better structure. The key metric? P/Div ratio.
Cited sites scored 0.8 on P/Div ratio vs 0.2 for random sites. That's a +300% difference the second-biggest gap in our entire study.
+300% Better HTML Structure
Cited sites use semantic HTML that's easy to extract
0.8
Cited Sites P/Div Ratio
0.2
Random Sites P/Div Ratio
+300%
Difference
GOOD: Cited Sites
Semantic HTML with proper <p> tags
<article>
<p>Clear, semantic content here</p>
<p>Another paragraph of substance</p>
<p>LLMs can easily extract this</p>
</article>
✓ Content is clearly identified
✓ Easy for AI to parse and extract
✓ Semantic meaning preserved
BAD: Random Sites
Generic <div> soup with no semantic meaning
<div class="wrapper">
<div class="content">
<div class="text">Content buried in divs</div>
<div class="text">Hard to extract</div>
</div>
</div>
✗ No semantic structure
✗ Content lost in nested divs
✗ Harder for AI to parse
What is P/Div Ratio?
P/Div ratio measures semantic HTML quality by dividing the number of <p> tags by <div> tags.
Why it matters: LLMs can extract content more easily when it's properly tagged. Use <p> for paragraphs, <article> for main content, and save <div> for layout.
Schema Markup is Basically Useless
Yeah, we said it. Schema markup showed only a +0.8% difference between cited and random sites. Statistically irrelevant.
Only 33.3% of cited sites even had Article schema, yet they still got cited. This doesn't mean schema is bad, it's just not a deciding factor for LLM citations.
However, 83% of the cited websites use JSON-LD, so I'll keep adding it here just in case.
The takeaway: If you have to choose between writing great content and perfecting your schema markup, write great content. Every time.
The Common Patterns
After analyzing 60 sites and 74 different metrics, clear patterns emerged. Here's what the top-performing cited sites have in common.
Pattern #1: They Answer Directly, Then Go Deep
100% of our top 10 sites scored perfect 10/10 on answer completeness. They didn't bury the lede or make you scroll forever. They answered the question in the first few paragraphs, then backed it up with depth.
This isn't about being superficial, it's about being structured. Give the direct answer, then provide the context, data, and nuance that proves you know what you're talking about.
Pattern #2: They Write Like Insiders, Not Outsiders
The top sites used industry jargon naturally. One site had 109 acronyms in a single article about drones. Another had 29.33% long technical words in an affiliate marketing piece.
They didn't explain every term like they were writing for beginners. They assumed their audience had basic knowledge and went straight to the advanced stuff. That confidence signals expertise.
Pattern #3: They Use Lists and Structure Liberally
Cited sites averaged 20.8 lists per article (vs 18.6 for random sites). They broke information into scannable bullets, numbered steps, and organized hierarchies.
Why? Because it makes information actionable. "Top 10 AI Tools" naturally becomes an ordered list. "Benefits of X" becomes bullet points. LLMs can extract this structured information cleanly.
Pattern #4: Quality Over Quantity, Every Time
Remember: cited sites were 23.8% shorter than random sites (1,493 vs 1,960 words), yet they had:
Richer vocabulary
More technical depth
Better structure
Higher information density
The random sites stuffed in extra words to hit some arbitrary length target. The cited sites said exactly what needed to be said, then stopped.
Pattern #5: They're Concise But Complete
Here's a mind-bender: the shortest site in our top 10 was 527 words long. The longest was 5,685 words. Both got cited.
What they shared? Vocabulary efficiency. The 527-word article had a Type-Token Ratio of 0.6243, the highest in our entire dataset. Every word counted. No fluff, no repetition, just dense, expert-level information.
Pattern #6: Recency Isn't Optional
9 out of 10 top sites were published in 2025. The one exception was robertyoung.consulting (our #1 ranked site), which had no publication date listed, though given its high performance and the nature of its content (discussing supplements "popular in 2025"), it's likely recent even if we couldn't verify the exact publication date.
The Anti-Patterns (What *Doesn't* Work)
Just as interesting as what works is what doesn't work:
❌ Long author bios (random sites had more)
❌ Credentials sections (random sites had more)
❌ Disclosure statements (random sites had more)
❌ External links (random sites had 50% more)
❌ FAQ schema (random sites had more)
All those traditional EEAT "trust signals" that work for Google seem not to be that relevant for AI search citations, at least for these small websites with low domain authority.
The Formula (If We Had to Boil It Down)
Based on our composite scoring (which predicted citations with decent accuracy), here's the rough formula:
The Citation Formula
What actually matters for getting cited by ChatGPT
30% Recency
Current year content (2025/2026)
30% Originality
Unique angle + proprietary data + nuance
20% Expertise
Technical depth + insider knowledge
15% Vocabulary
Rich language + technical terms + acronyms
5% Structure
Clean HTML + proper tags + lists
40% Originality (unique angle + proprietary data + nuanced analysis)
Plus a multiplier: Is it from 2025/2026? If no, your odds drop by ~75%.
What This Means for You: A Generative Engine Optimization Strategy
If you want ChatGPT to cite your content, your SEO for ChatGPT strategy should focus on:
Publish or update to the current year (2025/2026)
Have a unique take backed by real data
Write with sophisticated vocabulary and technical terms
Use semantic HTML (<p> tags, <article>, lists)
Answer directly, then go deep
Be concise but complete, cut the fluff
In summary, write like an expert, publish fresh content, be technically precise and make it extractable. This generative engine optimization approach differs from traditional SEO. It's about content quality that AI search engines can recognize and extract, not about gaming algorithms with backlinks and keywords.
FAQ: Getting Your Content Cited by ChatGPT
How do I get ChatGPT to cite my website?
Focus on three core factors: publish fresh content (2025/2026), demonstrate unique expertise with original insights or data, and make it easily extractable with semantic HTML. Our research found that 83.3% of cited sites were from the current year, and they averaged 77.1% on originality scores (unique angles + proprietary data). Write like an expert explaining something to a peer, not like you're optimizing for a search algorithm.
Does domain authority matter for LLM citations?
Yes, domain authority still matters for LLM citations. According to the Savannabay 60-keyword study, which analyzed 2,410 citations across Google Search, Google AI Overview, ChatGPT, and Perplexity, the average domain authority requirement is almost identical among all platforms (only a 5.1-point difference). For competitive short-tail queries, LLMs still favor high-authority domains (DR 75–80+), much like traditional SEO. But for mid- and long-tail queries, authority requirements drop sharply (12–30%), allowing smaller or niche sites to be cited when their content is specific, recent, and directly answers the question.
However, ChatGPT shows the highest variability of all platforms, with a very large standard deviation (±30–36 DR points). This means it can cite both extremely low-authority sites (DR 0–1) and very high-authority sites (DR 90+) for the same type of query.
That's where small websites can thrive. If you write original content demonstrating expertise, with a fresh date, a 20% vocabulary density, you are in the right path.
Do I need schema markup to get cited by ChatGPT?
No. Schema markup showed only a +0.8% difference between cited and random sites, statistically irrelevant. Only 33.3% of cited sites had Article schema, yet they still got cited.
That said, 83% of cited sites use JSON-LD markup (various types, not just Article schema), suggesting it's become standard practice. Since it's technically easy to implement and doesn't hurt, include it. Just don't prioritize it over writing great content.
Priority order: Original content > Fresh dates > Technical vocabulary > Clean HTML > Schema markup
How long should my content be to get cited?
There's no magic number. The shortest cited site in our top 10 was 527 words. The longest was 5,685 words. Both got cited.
What they shared was vocabulary efficiency: every word counted. The 527-word article had the highest Type-Token Ratio (0.6243) in our entire dataset, meaning it used incredibly diverse vocabulary without repetition or fluff.
Cited sites averaged 1,493 words vs 1,960 for random sites, 23.8% shorter, yet they packed more technical depth, richer vocabulary, and higher information density. Quality over quantity, every time.
How recent does my content need to be?
Current year only. 83.3% of cited sites were published in 2025 vs 23.3% of random sites, a +257% difference, the biggest gap in our entire study.
Even content from 2024 (just one year old) barely got cited: zero cited sites vs 8 random sites. ChatGPT's web search specifically looks for fresh information not in its training data.
Action items:
Update old content with 2025/2026 dates
Reference current year explicitly ("In 2025..." not "Recently...")
Add "Updated: [Month] 2025" notices
Use schema.org datePublished and dateModified with current dates
What's the fastest way to improve my chances of getting cited?
Short-term wins (do this today):
Update your publication dates to 2025/2026
Add semantic HTML (<article>, proper <p> tags for content paragraphs)
Mention the current year explicitly in your text
Structure content with lists (makes it extractable)
Medium-term improvements (do this this week):
Rewrite your intro to answer the question directly in the first 2-3 paragraphs
Add technical terminology and industry jargon naturally
Include a unique angle or perspective others haven't covered
Remove fluff, cut 20-30% of words without losing substance
Long-term competitive advantage (do this this month):
Conduct original research (surveys, tests, case studies)
Develop proprietary data or analysis
Build genuine domain expertise to write with technical depth
Create content with nuanced analysis (trade-offs, context-dependent recommendations)
The highest-impact action? Publish something original with data no one else has. Sites with proprietary data scored 8-10/10 on that dimension and massively outperformed generic content.
What about content structure: should I optimize my HTML?
Yes, but focus on semantic quality over quantity. Cited sites scored 0.8 on P/Div ratio vs 0.2 for random sites (+300% difference).
Cited sites also used 20.8 lists per article vs 18.6 for random sites. Lists make information actionable and extractable, perfect for LLM parsing.
Is there a formula for what makes content citable?
Based on our composite scoring model that predicted citations with decent accuracy:
40% Originality (unique angle + proprietary data + nuanced analysis)
Plus a critical multiplier: Is it from 2025/2026? If not, your odds drop ~75%.
This isn't a perfect formula, but sites scoring 70+ using these weights had significantly higher citation rates than sites scoring below 50.
Research basis: Analysis of 60 low-authority websites (DR < 15) across 74 metrics, comparing 30 sites cited by ChatGPT vs 30 non-cited sites answering identical questions. Dataset: oficial.csv, 2026-01-22.
Methodology: How We Conducted This Research
We analyzed 60 low-authority websites (Domain Rating < 15) using ChatGPT's web search feature: 30 sites ChatGPT cited and 30 control sites from organic search answering identical queries. All sites verified with DR 0-14 (median: 3.5), word count 527-5,685, publication years 2019-2025, collected January 15-18, 2026.
Vocabulary Density (Python/NLTK): Type-Token Ratio (cited: 0.4619 vs random: 0.399), long words % (17.87% vs 14.94%), acronyms (28.7 vs 23.03), content word ratio.
HTML Structure (PowerShell): P/Div ratio (0.8 vs 0.2), semantic tags, heading hierarchy, list usage.
Schema Markup (Python): Article schema completeness (5.23/9 vs 4.93/9, not significant).
Recency: Publication dates extracted from schema/meta tags. 2025: 83.3% cited vs 23.3% random (χ² = 24.8, p < 0.001).
T-tests for normally distributed data, Mann-Whitney U for non-parametric, Chi-square for categorical. Significance threshold: α = 0.05. Largest effects: Recency +257% (p < 0.001), P/Div Ratio +300% (p < 0.01), Long Words +19.6% (p < 0.05), TTR +15.76% (p < 0.05).
Limitations
Sample size: n=30 per group (power ~0.65), confidence intervals ±10-15%. Selection bias: English queries only, informational focus, B2C niches. Temporal validity: January 2026 data, ChatGPT-specific. Causation: Observational study identifies correlations, not causal relationships.
Conclusion
While our sample size limits statistical power, the observed patterns are strong enough (particularly for recency and P/Div ratio) to provide actionable insights. The +257% recency difference and +300% P/Div difference show effect sizes large enough to be practically significant even with n=30.
Luiz Gustavo is full-stack developer in Savannabay and Gobrunch, Computer Science student
Richard Lowenthal is founder of Savannabay, co-founder of GoBrunch and Live University, AI Search & GEO enthusiast


.png)

.png)



.png)